Research
次世代気象予報モデルの大規模GPUコンピューティング
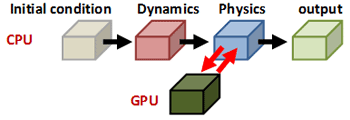
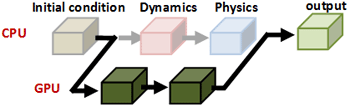
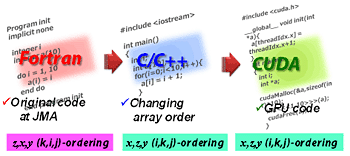
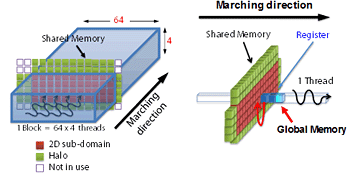
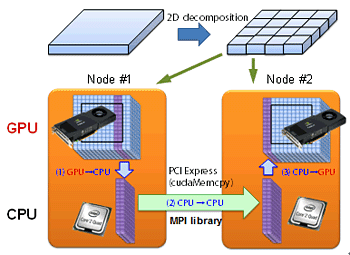
気象予報は我々の日常生活にとって不可欠なものとなっています。台風などの災害情報は防災の観点からも非常に重要です。この気象計算はスパコンを利用する代表的な大規模計算の一つですが、非静力(鉛直方向に重力と気圧勾配の釣り合いを仮定しない)のメソスケール・モデルでは雲を解像する格子点数が必要となり、より大規模な計算が必要です。 気象予報にとって、できるだけ短時間で計算を終了させることは大きな課題です。世界標準の気象コードとなりつつあるWRF(the Weather Research and Forecasting model)の開発グループでは、いち早くGPU を利用する取り組みを開始しました。彼らはWRFの物理過程における計算負荷の高いモジュールを GPU に移植し、高速化を図りました[1]。全体の計算は従来通り CPU 上で実行するのですが、GPU 化したモジュールを計算する際にはCPUのメモリからGPUのボード上のビデオメモリに必要なデータを転送しGPUで計算します。GPUで計算した結果はGPUのビデオメモリに出力されるため、CPUでWRFの計算を続行させるためにはGPUからCPUのメモリへのデータ転送が必要になります。気象計算では、時間発展を計算しますので、WRFの計算の毎ステップでCPU-GPU 間の通信が発生します。この通信時間が大きなボトルネックとなり、GPUに移植したモジュール単体での計算はCPUで計算する場合の20 倍の高速化に成功したのですが、計算全体では 30% 程度の速度向上に留まってしまい、GPU の持つ本来の性能を十分に発揮できていません[1]。 GPU コンピューティングにより高い実行性能を達成するには、可能な限りCPU-GPU 間の通信を排除する必要があります。そのためには、初期条件の部分を除く気象モデルの全てのサブルーチン(関数)をGPU化しなければなりません。WRFコードは膨大であり、世界中の多数の研究者が参加して開発を行っているため、コードの全ての部分を一部の研究者しか理解できないGPUコンピューティング(CUDA)言語に変更するのは無理な話です。 そこで我々は気象庁の数値予報課と協力し、気象庁で次期気象予報モデル(天気予報)として開発されているASUCA [2]の全てのモジュールをGPU化することにしました。完全GPU化するには、ASUCA の膨大なコード全体をスクラッチからCUDAに書き直す必要があります。一般に気象モデルは物理過程と力学過程から構成されていますが、物理過程の各モジュールは単体でGPU化が容易に行えます。力学過程の計算は隣接格子点へのアクセスを伴うため、予報変数を終始GPUのビデオメモリ上に確保し、関係するモジュールを同時にGPU化する必要があります。力学過程は圧縮性流体力学の方程式に基づいているため、演算よりメモリアクセスが支配的な計算になっています。GPU はビデオメモリへのアクセス速度(メモリバンド幅)も150GB/sec以上(CPUの数倍以上)であり、力学過程においても十分高速な計算が期待できます。 オリジナルのASUCAのコードはFORTRANプログラミング言語で記述されているため、我々は一旦C/C++ 言語に書き直し、その後、CUDAに書き換えました。FORTRAN版では力学過程の格子点計算が3重ループになっていて、その最内側ループが格子点数の少ない鉛直方向になっています。さらに鉛直方向には逐次性のある計算が含まれるためGPUコンピューティングに向いません。そこでCUDAのコードでは、最内側にアドレスが連続になる水平方向を選び、 ループに代えて格子点数と同数のスレッドを実行させるようにしました。この大変更のために、C/C++言語に書き換え、中間で検証を行いました。 さらにストリーミング・マルチプロセッサ内の共有メモリをキャッシュ的に使うアルゴリズム(Software Managed Cache)やレジスタを有効利用するなどの多数の技法を導入し、最終的に学術国際情報センターのTSUBAME 2.0にも使われているIntel CPU Xeon X5670 の1ソケット(6コア)に対して、NVIDIA GPU Tesla M2050 の1ソケット(448 CUDAコア)で計算することで約12倍の高速化を達成しました[3]。 実はもう一つの問題点があります。GPUはボード上にせいぜい数GBのビデオメモリしか持ちません。実際の気象モデルは数100GBのメモリを使うので、1個のGPUでは少な過ぎます。従って、複数GPUを用いた大規模計算を行うために、CPUで計算するときと同じように単体GPUカードのメモリで計算可能なサイズにまで計算領域を細かく分割し、それを各GPUに割り当てる必要があります。CPUのマルチノードの並列計算と違うのは、現時点のCUDAではGPUのメモリ間のデータの直接通信を行うことができず、CPU側のメモリを介して通信しなければならない点です。 |
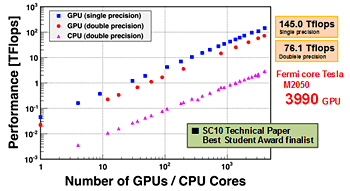
大規模計算ではGPU間のデータ通信が大きなオーバーヘッドになるため、通信時間を隠ぺいするために計算とのオーバーラップの技術を導入しました。これらにより、ASUCAのGPU版はTSUBAME 2.0 の 3990個のGPUを使って145TFLOPS(単精度)という非常に高い実行性能を達成することができました[4]。
現在、気象庁では水平5kmの格子を使って数値予報を行っています。気象庁の将来の目標は500m格子で気象予報を行うことですが、我々はGPU版のASUCAを使い、現在の数値予報に用いている初期値・境界データに対して、TSUBAME 2.0 の 437 GPU を使って水平500m格子(4792×4696×48)の計算をすることができました。水平解像度500m格子の計算は5km格子の場合と比較して詳細に雲の様子を計算していることが分かります。この結果は地域の気象予報に直結しますので、現時点で500m格子で日本全土を含む領域を計算できたことは大きな意義があります。
GPUコンピューティングにより、実運用を目指している気象予報モデルをCPUで計算するよりも10倍以上高速に計算でき、さらに10倍以上少ない消費電力で計算できることができました。
参考文献
報 道
|
|||||
水平解像度500m格子を用いてメソスケール気象モデルASUCAで計算した雲分布(動画) |
||||||